第八章 一用就会的数据库
数据库术语中的“表”是什么意思?
表就是被整理成表格形式的数据
键和索引的区别是什么?
键用于设定表和表之间的关系,而索引是提升数据检索速度的机制
8.1 数据库是数据的基地
所谓数据库 Database 就是数据 Data 的基地 Base。在实施企业的商业战略时,如果企业的数据散布在各个地方,在更新和检索时就要花费大量实践,分析起来就会很麻烦。
适合存储大规模数据的是关系型数据库。在关系型数据库中,数据被拆分整理到多张表中,同时表与表之间的关系也可以被记录下来。
8.2 数据文件、DBMS 和数据库应用程序
为了编写数据库应用程序,一般情况下会借助一个称作 DBMS 的软件。
数据库的实质虽然是某种数据文件,但是一般我们编写的应用程序并不是直接去读写这些数据文件,而是通过 DBMS 作为中介简介地读写。DBMS 不但可以使应用程序轻松的读写数据文件,而且还具有一致并安全地存储数据的功能。
数据库系统的构成要素包括“数据文件”,“DBMS”,“应用程序”三部分。
在小型系统中,把数据文件部署在一台计算机上,称作“独立性系统”。
在中型系统中,把数据文件部署在一台计算机上,并且使数据文件被部署了 DBMS 的应用程序的多台计算机共享,这样的系统称为“文件共享型系统”
在大型系统中,把数据文件和 DBMS 部署在一台或者多台计算机上,然后用户从另外一些部署这应用程序的计算机上访问,这样的系统被称作“客户端/服务器型系统”。
8.3 设计数据库
假设我们要开发一个酒铺管理的应用程序。
首先从设计数据库开始。
而设计数据库的第一步是从“你想要了解什么”的视角出发找出需要的数据。
在酒铺管理的应用程序中,客户需要知道什么?
- 商品名称
- 单价
- 销售量
- 顾客姓名
- 住址
- 电话号码
把必要的数据筛选出来以后,下一步要考虑的是各种数据的属性。属性也称作模式,具体来说就是数据的类型,数字的话是整数还是小数,字符串的话最多允许包含多少个字符,是否允许 NULL 值,等等。
在关系型数据库中,把录入到表中的每一行数据都称为记录,把构成一条记录的各个数据项所在的列都称作字段。
记录有时也被称行或者元组,字段有时也被称为列或者属性。
8.4 通过拆表和整理数据实现规范化
既然表已经准备好了,那么只需要把带有界面并且能够读写数据的应用程序做出来,就大功告成了。可实际上并非如此,这里由两个问题,第一个是用户不得多次录入相同的数据,另一个问题是,录入的名称不同指代的却是相同的商品。
为了解决这类问题,在设计关系型数据库时,还要进行“规范化”。所谓规范化,就是将一张大表分割成多张小表,然后再在小表之间建立关系,以此来达到整理数据库结构的目的。通过规范化,可以形成结构更加优良的数据库。
规范化的要点是在一个数据库中避免重复存储相同的数据。
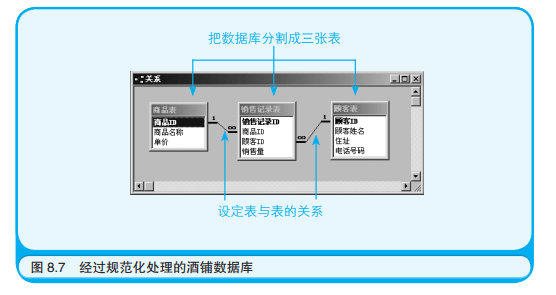
在本例子中,把酒铺的数据库分为“商品表”“顾客表”和“销售记录表”三张表,然后再在它们之间建立关系。通过这样的梳理,既省去了多次重复录入相同的顾客姓名、住址、电话号码的麻烦,又能防止把相同的商品名称输入成不同名称的错误。
8.5 用主键和外键在表间建立关系
为了在表间建立关系,就必须加入能够反映表与表之间关系的字段,为此所添加的新字段就被称为键(Key),首先要在各个表中添加一个名为主键(Primary Key)的字段,该字段的值能够唯一地表示表中的一条记录。
如果试图录入在主键上含有相同值的记录,DBMS 就会产生一个错误通知,这就是 DBMS 所具备的一种一直并且安全地存储数据得机制。
在销售记录表上,还要添加顾客 ID 和商品 ID 字段,这两个字段分别是另外两张表的主键,而对于销售记录表来说,它们就都是“外键”。通过主键和外键上相同的值,多个表之间就产生了关联,就可以顺藤摸瓜取出数据。
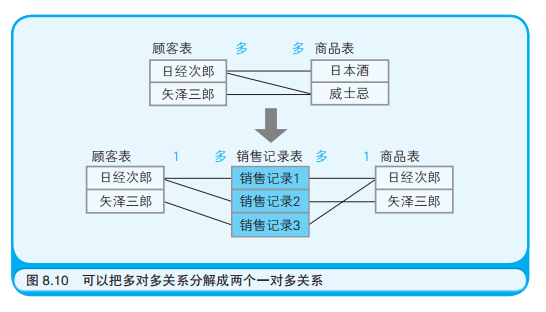
记录之间虽然在逻辑上由一对一,一对多,以及多对多三种关系,但是在关系型数据库中无法直接表示多对多关系。当出现多对多关系时,可以在这两张表之间再加入一张表,把多对多关系分解成两个一对多关系。
DBMS 还具有检查参照完整性的功能,这种机制也是为了一直并安全地存储数据。例如,在目前的酒铺数据库中,如果从商品表中删除了“日本酒”这条记录,那么在销售记录表中,曾经记录着买日本酒的记录就不能说明买的是什么商品的了。
如果没有参照完整性等方面的检查,用户就可以任意的执行删除数据之类的操作。而 DBMS 能在这种问题上起到防范于未然的作用,确实是一种很方便的工具。
8.6 索引能够提升数据的检索速度
可以在表的各个字段上设置索引,这也是 DBMS 所具备的功能之一。虽然索引和键这两个概念容易让人混淆,但其实两者是完全不同的。
索引仅仅是提升数据检索和排序速度的内部机制。一旦在字段上设置了索引,DBMS 就会自动为这个字段创建索引表。
索引表是一种数据结构,存储着字段的值以及字段所对应记录的位置。
一旦设置了索引, 每次向表中插入数据时, DBMS 都必须更新索引表。 提升数据检索和排序速度的代价, 就是插入或更新数据速度的降低。 因此, 只有对那些要频繁地进行检索和排序的字段, 才需要设置索引。
8.7 设计用户界面
略
8.8 CRUD
为了对数据库进行 CRUD 操作, 就必须从应用程序向 DBMS 发送命令。 这里所使用的命令就是 SQL 语言( Structural Query Language,结构化查询语言)。
下面给诸位展示一个 SQL 语句的例子, 可以看出它和英文的句子很像。
SELECT 顾客姓名 , 住址 , 电话号码 , 商品名称 , 单价 , 销售量
FROM 顾客表 , 商品表 , 销售记录表
WHERE 顾客表 . 顾客姓名 = "日经次郎"
AND 销售记录表 . 顾客 ID = 顾客表 . 顾客 ID
AND 销售记录表 . 商品 ID = 商品表 . 商品 ID ;使用 JS 来描述以下
顾客表 , 商品表 , 销售记录表.map(item=>{
if(
.顾客表顾客姓名 == "" &&
销售记录表.顾客 ID = "" &&
销售记录表 . 商品 ID = ""
){
return {
item.顾客姓名 ,
item.住址 ,
item.电话号码 ,
item.商品名称 ,
item.单价 ,
item.销售量
}
}
})8.9 使用数据对象向 DBMS 发送 SQL 语句
8.10 事务控制也可以交给 DBMS 处理
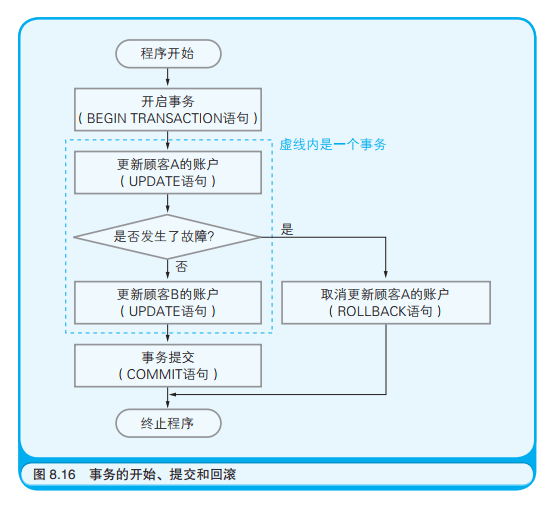
最后介绍 DBMS 的一个高级功能——事务控制。
事务由若干条 SQL 语句构成,表示对数据库一系列相关操作的集合。
有一个经典的银行账户间汇款的例子可以用于说明其概念。 为了从顾客 A 的账户中 给顾客 B 的账户汇入 1 万日元, 就需要将以下两条 SQL 语句依次发送给 DBMS : 1. 把 A 的账户余额更新( UPDATE 语句) 为现有余额减去 1 万日元; 2. 把 B 的账户余额更新( UPDATE 语句) 为现有余额加上 1 万日元。 此时这两条 SQL 语句就构成了一个事务。
假设在第一条 SQL 语句执行后,网络或者计算机发生了故障,第二条 SQL 语句无法执行的话,A 的余额减少了 1 万日元,但是 B 的余额却没有想要的增加一万日元,这就导致了数据不一致。
为了防止出现这种问题,在 SQL 语言中设计了以下三条规则:
- BEGIN TRANSACTION 用于通知 DBMS 开启事务
- COMMIT 用于像 DMBS 提交事务
- ROLL BACK 用于在事务进行中发生问题时,把数据恢复到事务开始前的状态